Testy A/B to podstawa – usłyszysz z ust 99% osób zajmujących się marketingiem w internecie. Testuj WSZYSTKO – powiedzą ci głębiej siedzący w temacie.
Delikatnie rzecz ujmując – są w błędzie. Ogólnie testy A/B są najlepszym sposobem na porównanie skuteczności naszych nowo wprowadzanych działań z poprzednio funkcjonującymi procesami.
Gdy przejdziemy do szczegółów okazuje się, że większość przeprowadzanych testów to bezsensowne działania których wyniki są kompletnie bez znaczenia. Nie oznacza to, że nie powinno się ich robić. Warto i należy – trzeba tylko wiedzieć kiedy.
Test A/B to BADANIE NAUKOWE
Z definicji, testy A/B to metoda badań naukowych polegająca na równoległym sprawdzeniu skuteczności działania dwóch wersji badanego narzędzia. Mniej encyklopedycznym językiem – wprowadziliśmy zmianę w sklepie internetowym i chcemy sprawdzić jak przełoży się na ilość zakupów. Tworzymy dwie wersje strony – nową i starą (tzw. kontrolna) i puszczamy odwiedzających na losowo wybraną wersję. Po jakimś czasie wiemy już, że nowa strona sprzedaje lepiej lub gorzej. Odbywa się to według prostego schematu przedstawionego poniżej (źródło: vwo.com):
Testować można praktycznie wszystko – od całych stron www, przez kreacje emailowe, tematy, kolory i rozmieszczenie przycisków itp. Jest też wystarczająco dużo narzędzi – płatnych (np. Visual Web Optimizer) czy darmowych (eksperymenty Google Analytics).
Metoda wydaje się idealna – w identycznych warunkach porównujemy dwie lub więcej (testy A/B/X) wersji, dzięki czemu otrzymujemy maksymalnie wiarygodne rezultaty.
Znakomicie. Z tym, że nie zawsze. Z definicji, testy A/B to badanie naukowe z dziedziny statystyki – i jako takie powinny być przeprowadzane i oceniane w duchu naukowym. Tu pojawia się problem wiarygodności badań, na którym właśnie wykłada się większość testów.
Z badaniami statystycznymi wiążą się pojęcia istotności statystycznej i przedziału ufności.
Większość testów A/B nie jest istotna statystycznie.
Na szczęście temat jest prostszy niż brzmi. Przedział ufności to prawdopodobieństwo. Jest to liczba z zakresu 0-1. Im większa – tym większe prawdopodobieństwo, że badanie jest istotne statystycznie. W badaniach statystycznych najczęściej korzysta się z przedziału 0.9 do 0.99 – przedział 0.95 oznacza, że na 95% wynik badania jest miarodajny i wiarygodny.
Przyjęty w badaniu przedział ufności jest ściśle powiązany z wielkością badanej próby – czyli im bardziej prawdopodobne wyniki chcemy uzyskać, tym większą próbę musimy poddać badaniu. Bardzo logiczne – jeśli sprawdzimy nowy sklep na próbkach 100 osób, z których jedna lub dwie dokonają zakupu – wyniki prawdopodobnie nic nam nie powiedzą. Wystarczy, żeby jedna z kupujących osób zostałaby przerzucona do drugiej grupy, i otrzymujemy zupełnie inny rezultat.
Poziom 0.9 to absolutne minimum w badaniach marketingowych – z reguły przyjmuje się 0.95. Żeby nasz test miał sens, pozostaje nam policzenie, jak dużych próbek potrzebujemy do badania.
Drugim czynnikiem, od którego zależy wielkość próbki jest uzyskany wynik. Im większa różnica w badanych grupach, tym mniejszej próbki potrzebujemy. Jeśli mamy test A/B z próbkami po 1000 osób, w próbce A doszło do 100 zakupów, a w B do 104 zakupów – niewiele nam to mówi. Jeśli jednak w A było to 30 zakupów, a w grupie B kupiło 300 osób – chyba znamy zwycięzce? 🙂
Wielkość próbki jest więc wynikiem równania z dwoma zmiennymi.
Na szczęście możemy posłużyć się prostymi kalkulatorami, np. Optimizely, które policzą wszytsko za nas.
Jak to działa w praktyce?
Przykładowo, nasz sklep ma konwersję 2%, czyli 2 na 100 osób dokonują zakupu. Chcemy sprawdzić, czy zmiany w sklepie wpłynęły na wzrost tego współczynnika. W kalkulatorze manipulujemy tylko jednym czynnikiem – poziomem wzrostu, jaki nas interesuje. Bezpośrednio wpływa on na wielkość próbki jakiej będziemy potrzebowali. Jeśli bowiem nowy sklep będzie dwa razy lepiej sprzedawał (wzrost konwersji o 100% do poziomu 4%) – prawdopodobnie zauważymy to dość szybko. Jeśli natomiast wzrost konwersji wyniesie tylko 10% (do 2,2%) – będziemy potrzebowali dużo danych, żeby taki wynik był wiarygodny – każdy zakup w jednej z grup będzie bowiem przechylał szalę na jej korzyść. W naszym przypadku – żeby uzyskać wiarygodne wyniki badań, dla wzrostu konwersji o 10% potrzebujemy 15 640 osób w każdej z grup – czyli bez mała 30 000 osób musi przejść przez test. Przy wzroście konwersji o 100% potrzebujemy już tylko 698 osób w każdej z grup. Spora różnica, prawda?
Łatwiej zastosować to do oceny istotności badań, które już przeprowadziliśmy – wiemy bowiem, jaki wzrost lub spadek udało się uzyskać. Dzięki temu po wpisaniu uzyskanych wyników wiemy, czy nasz test okazał się rozstrzygający. Jeśli nie – nie powinniśmy się sugerować jego wynikami, są kompletnie nieistotne.
Większość marketerów tego niestety nie sprawdza – obserwują kilkuprocentowy wzrost przy niewystarczająco dużej próbce i uznają, że jedna z wersji jest lepsza. W taki sposób można przeprowadzić kilkadziesiąt testów i na koniec dnia uzyskać takie same (lub gorsze) wyniki jak na początku.
Jakie zagrożenia niesie za sobą zastosowanie zbyt małej próbki
Nie wystarczy jednak, że skorzystamy z kalkulatora i wynik okaże się miarodajny. Zbyt mała próbka potrafi zakłócić wynik badania nawet mimo pozornie poprawnych wskaźników. Peep Laja z Markitekt pokazał na wymownym przykładzie, jak może skończyć się zbyt wczesne zakończenie testu A/B bez posiadania odpowiedniej ilości danych. Po dwóch dniach testu uzyskano następujące wyniki:
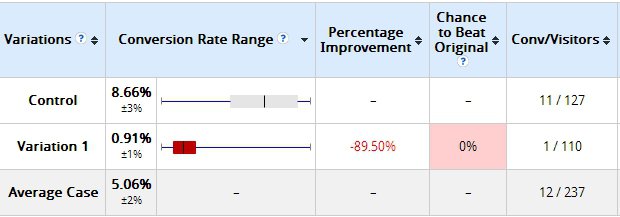
W grupie kontrolnej (stara wersja) na 127 wizyt odnotowano 11 konwersji, w grupie zmodyfikowanej (Variation 1) na 110 wizyt tylko jedna zakończyła się konwersją. Wyniki wydają się być jednoznaczne – nawet system używany do testu mówi, że szansa na pokonanie wersji kontrolnej wynosi.. 0%.
Sprawdźmy co mówi kalkulator Optimizely. Nie radzi sobie z ujemnymi procentami, więc odwrócimy sytuację – jako podstawowy test weźmy Variation 1, a grupę kontrolną (tą z wyższą konwersją) potraktujmy jako testowaną. Wprowadzamy więc dane. Konwersja wzrosła o 951%, pierwotna w naszym przypadku to 0,91%. Wynik – żeby wyniki były istotne na poziomie 95%, na każdą grupę musi przypadać po 31 osób.
Jak widzimy – przypada 3-krotnie więcej.
Przytomnie pozwolono testowi działać dalej. Po 10 dniach wyniki wyglądały już następująco:

Zmiana o 180 stopni. Grupa kontrolna uzyskała gorsze wyniki, niż skazana na porażkę wariacja numer 1. Sprawdźmy w Optimizely, czy możemy już zatrzymać test. Konwersja wyjściowa – 13,66%, konwersja uzyskana w drugiej grupie – 17,10%, co daje wzrost o 25,18%.
Werdykt – cóż, wciąż za wcześnie. Potrzebna jest 2 razy większa próbka.

Jak zatem widać, test A/B może dać dwa różne wyniki w zależności od wielkości próbki. Nie wiadomo, co stałoby się z powyższym przykładem gdyby dojść do zakładanych 1274 konwersji.
Powstaje jednak problem – testy nie mogą trwać w nieskończoność – najlepiej byłoby mieć wyniki już po 1-2 tygodniach. Jeśli testujemy konwersje np. na ostatnim kroku przed akceptacją lub porzuceniem zamówienia – możemy chwilę poczekać na wyniki. Co zrobić w takim przypadku?
Można iść na ustępstwa – zmniejszyć wielkość próbki kosztem poziomu istotności. W powyższym przykładzie wyniki byłyby statystycznie istotne, ale na poziomie istotności około 0.8. Patrząc na to w prosty sposób – na 80% wyniki są prawidłowe, a tylko na 20% nie są – jest więc czterokrotnie większa szansa, że wersja Variant 1 faktycznie jest lepsza. Prawdopodobnie pozwoliłbym testowi dojść do pełnych dwóch tygodni, i jeśli trend utrzymałby się – wybrałbym Variant 1 do dalszych prac. Poziom 0.8 to za mało do badań naukowych, ale jest akceptowalny jeśli nie mamy innego wyjścia w marketingu. Jeśli jednak poziom spadnie poniżej tej wartości – badanie niewiele nam powie. Przy projektowaniu testu A/B upewnijmy się, że uda nam się w rozsądnym czasie (nie mniej niż tydzień, nie więcej niż miesiąc. Optymalne są dwa-trzy tygodnie) uzyskać wyniki z poziomem istotności powyżej 0.9.
Kiedy przeprowadzenie testu A/B ma sens
Nie ma jednej odpowiedzi, łatwiej powiedzieć, kiedy nie robić. Generalnie – żeby test miał sens powinien trwać od 1 do 3-4 tygodni. Nie krócej, bo zachowania klientów najczęściej zmieniają się w zależności od dnia tygodnia, więc tydzień to absolutne minimum, najlepiej zaś przedłużyć test do dwóch pełnych tygodni lub więcej, jeśli pozwala nam na to sytuacja. Wyjątkiem są firmy, w których mamy pewność (na podstawie danych historycznych), że aktywność klientów nie zależy od dnia tygodnia – czyli wskaźniki odrzuceń, konwersji czy czasu na stronie są na względnie stałym poziomie. W takiej sytuacji, jeśli testujemy dwie wersje dające skrajnie odmienne wyniki (np konwersja 15% w stosunku do 3% w wersji kontrolnej) możemy skrócić test. Żeby jednak nie wpaść w pułapkę opisaną na przykładzie z poprzedniego paragrafu, załóżmy sobie minimalną ilość konwersji od której zabierzemy się za ocenę wyników testów. Są różne drogi do wyboru odpowiedniej wersji, ogólnie przyjmuje się 100 konwersji w każdej z grup jako sensowne minimum. Jeśli pozwalają nam na to warunki, zwiększyłbym tę liczbę do minimum 200 konwersji.
Jak sprawdzić w praktyce czy mamy odpowiednie warunki do testu A/B
Jeśli nie ufamy obliczeniom (jak widać, sprawdzają się lepiej przy dużym ruchu) łatwo sprawdzić empirycznie czy ma sens robienie testów w naszym przypadku. Wystarczy zrobić test A/B … z identycznym wersjami w obu grupach. Obserwowałem zadziwiające wyniki – dwie grupy po 1000 kontaktów (email marketing) otrzymały identyczną wiadomość w tym samym czasie. CTR w jednej z grup – 6,7%. CTR w drugiej – 9,2%.
37% wyższa klikalność, a maile były takie same! Jeśli obserwujemy takie różnice – mamy pewność, że wynik jest fałszywie pozytywny i test na tej grupie nic nam nie da. Jeśli w naszej grupie testowej różnice będą się kształtowały na poziomie 2-4% – możemy pomyśleć o rzeczywistych testach.